es搜索引擎的原理_es 写入数据的原理,查询数据的原理和倒排索引(3)

JPG,1920x1030,134KB,500_268
多线程爬虫和es搜索引擎实战

JPG,985x516,234KB,499_261
你往es里写的数据,实际上都写到磁盘文件里去了,磁盘文件里的数据操作系统会自动将里面的数据缓存到os cache里面去_ es的搜索引擎严重依赖于底层的filesystem cache,你如果给filesystem cache更多的内存,_ (1)性能
JPG,609x422,132KB,360_250
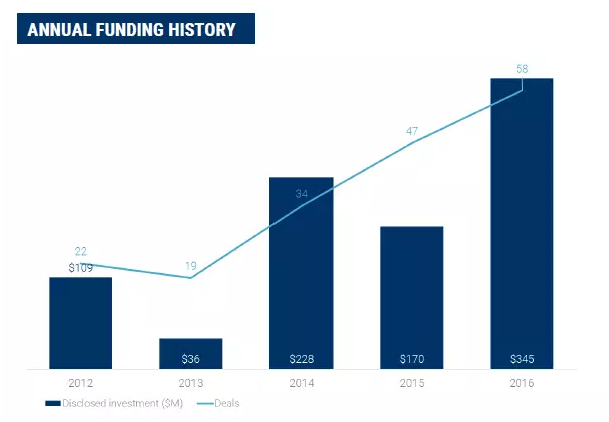
在该领域值得关注的初创企业包括为零售商提供地理位置服务的databerries、商业领域的聊天机器人niki.ai、服装领域的vue.ai,店内消费者行为分析公司mod.cam和电商搜索引擎公司twiggle等.
JPG,924x446,231KB,519_249
面试3连炮 聊聊ES写入数据的原理 查询数据的原理 倒排索引了解吗
JPG,500x321,231KB,389_250
解释为什么es可以做到近实时搜索
JPG,647x394,231KB,500_304
这里的一个重点就是我们的分布式搜索引擎了,在前面我们聊过lucene,而es、solr的底层其实都是lucene.
JPG,1828x953,231KB,480_250
基于关系型数据库和ES搜索引擎实现多源百亿级数据的数据分析方案
JPG,944x592,231KB,399_250
实时更新搜索引擎,如es中的索引信息_ 实时更新redis中的缓存_ 发送到kafka供下游消费,由业务方自定义业务逻辑处理等_ 因此,通常我们把binlog syncer单独作为一个模块,其只负责解析从数据库中拉取并解析binlog,并在内存中缓存

JPG,803x448,231KB,447_249
clinical queries 专为临床医生设计的搜索引擎
JPG,878x555,231KB,500_316
duckula以kafka等消息中间件为中心,用消息来进行削峰填谷的作用,消息可以做为消息驱动微服务的驱动器,也可以入es等分布式搜索引擎 来实现实时搜索.

JPG,980x560,231KB,437_250
mysql 主从复制与读写分离概念及架构分析

JPG,655x495,134KB,331_250
它提供了一个分布式多用户能力的全文搜索引擎,基于restful web接口._ es的好处在于,本身就是为云及分布式设计,所以整体比较优化.

JPG,456x367,231KB,456_367
b) 分布式文件服务系统(tfs,gfs,nfs)把多个硬盘管理成本地硬盘可以直接读写_ 专项突破_ a) 架构示例_ b) 搜索引擎:人性化搜索()_ i. 全文检索工具(lucene.net----solr—es):分词二次存储,查询是再分词,